

Mit Automation Anywhere V39 KI-Automatisierung erweitert die Automation-360-Plattform gezielt ihre Funktionen für Künstliche Intelligenz. Ziel ist es, Automatisierungen schneller, transparenter und leichter wartbar zu gestalten. V39 richtet sich insbesondere an Anwenderunternehmen, IT-Architekten und Automatisierungsverantwortliche, die ihre IT-Landschaften mit intelligenten Automatisierungen ergänzen möchten.
Im Fokus stehen:
KI-gestützte Entwicklung für Entwickler und Fachanwender
Verbesserte Dokumentenverarbeitung
Transparenter Betrieb verteilter Automatisierungslandschaften
Integration in hybride ERP- und IT-Umgebungen
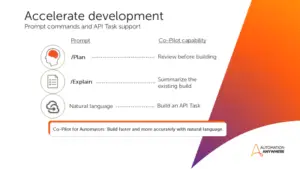
Co-Pilot für Automators wurde in V39 erheblich erweitert:
Plan-Modus: Wandelt Anforderungen in strukturierte, editierbare Automatisierungspläne um – ideal für Review und Teamabstimmung vor dem Build.
Explain-Funktion: Liefert verständliche Schritt-für-Schritt-Erklärungen für bestehende Automatisierungen – vereinfacht Debugging, Übergaben und Wartung.
API-Task-Support: Erlaubt das Erstellen, Bearbeiten und Aktualisieren von API-basierten Workflows per natürlicher Sprache.
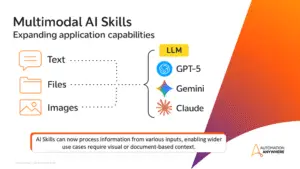
Multimodale AI Skills unterstützen nun Text, Bilder und Dateien und ermöglichen komplexe Szenarien wie Schadensanalysen, Dokumentenverarbeitung und visuelle Workflows. Entwickler können flexibel zwischen LLMs wie GPT-5, Gemini und Claude wählen.
Automator AI reduziert damit manuellen Entwicklungsaufwand, verbessert Konsistenz und beschleunigt hybride Integrationen zwischen Legacy-Software, Cloud-Services und externen Anwendungen.
V39 bringt erweiterte Funktionen für den Betrieb und die Analyse von Automatisierungen:
Process Metrics Dashboard: Überblick über Erfolgsquoten, Laufzeiten, Trends und Aging von Automatisierungen – mit Filter- und Exportfunktionen.
Mozart Orchestrator: Leistungsfähige Prozess-Orchestrierung, u.a. Universal Event Listener für Echtzeit-Auslöser in beliebigen Apps oder Systemen.
Agent Interoperability: Sichere, parallele Ausführung über mehrere Geräte und Plattformen; nahtlose Multi-Agent-Orchestrierung mit Governance und RBAC.
Diese Features sorgen für höhere Stabilität, schnellere Reaktionszeiten und bessere Analysefähigkeit in komplexen Automatisierungslandschaften.
Die Document Automation wurde in V39 stark erweitert:
Google Gemini Modelle auf AWS und GCP: Ermöglichen generative KI-gestützte Datenextraktion, unabhängig vom zertifizierten Cloud-Anbieter.
Effiziente Verarbeitung großer, unstrukturierter Dokumente
Unterstützung mehrsprachiger Dokumente
Verarbeitung komplexer Layouts
Schnellere und genauere Extraktion

Unterschied Oberfläche Document Automation V39
Version History in Test Mode: Verbesserungen ermöglichen sichere Änderungen an Lerninstanzen, automatische Validierung und korrekte Anzeige aller Versionen.
Fehlerbehebungen: Korrekte Extraktion deutscher Zeichen, Unterstützung asiatischer Zeichensätze, fehlerfreie Anpassungen von Standard Forms Projekten, stabile Adaptive Search Queries.
Generative Co-Pilot Validierung: Fehlende Signaturfelder werden korrekt erkannt und validiert.
Vorteile:
Reduzierter manueller Aufwand bei dokumentenintensiven Prozessen
Höhere Datenqualität und Genauigkeit
Flexibilität bei der Nutzung von Lerninstanzen auf verschiedenen Cloud-Plattformen
Bekannte Einschränkungen: Einige spezielle Szenarien im Testmodus, mit regulären Ausdrücken oder sehr langen Dateinamen müssen beachtet werden; Workarounds sind dokumentiert.
Die neue Version erleichtert Fachanwendern die Nutzung von Automatisierungen:
Einbettung direkt in Geschäftsanwendungen über iFrame-Widgets
Steuerung via natürlicher Sprache durch verbesserte Konversationsfunktionen
Erweiterte Wissensbasis für präzisere Automatisierungsanfragen
Das senkt die Einstiegshürde für nicht-technische Anwender und steigert die Nutzung von Automatisierungen im Fachbereich.
V39 ergänzt kontrollierte Zugriffe auf KI-Funktionen:
Generative Recorder: Zentral steuerbar und mit rollenbasierten Berechtigungen
Unterstützung für LLMs wie GPT-5, Gemini und Claude
Zugriffskontrolle und Governance über das Control Room Management
Damit wird die Zusammenarbeit zwischen Entwicklung, Betrieb und Compliance gestärkt.
Automation Anywhere V39 KI-Automatisierung vereint:
Schnellere, smartere Entwicklung
Stabilen, transparenten Betrieb
Einfache Einbindung von Fachanwendern
Besonders geeignet ist es für Unternehmen mit komplexen ERP-Landschaften, hybriden IT-Architekturen und datenintensiven Prozessen. V39 verbessert die Effizienz, Qualität und Steuerbarkeit von Automatisierungen, ohne Governance oder Nachvollziehbarkeit zu vernachlässigen.

Viele Unternehmen nutzen heute die Cloud, doch zwischen „Cloud nutzen“ und „Cloud richtig nutzen“ können Welten liegen. Während einige ihre Cloud-Infrastruktur als strategischen Vorteil einsetzen, kämpfen andere mit ineffizienten Systemen, steigenden Kosten und starren Strukturen. Der Unterschied liegt unter anderem in der Architektur: Wer von Anfang an auf eine durchdachte Cloud-Architektur setzt, schafft die Grundlage für Skalierbarkeit, Sicherheit und Effizienz. In diesem Artikel zeigen wir, was für den Aufbau einer Cloud-Architektur wichtig ist und wie die verschiedenen Ebenen zusammenwirken.
Eine zukunftssichere Cloud-Architektur entsteht durch bewusste Entscheidungen auf verschiedenen Ebenen. Von der grundlegenden Cloud-Strategie über die Anwendungsstruktur bis hin zur Automatisierung und Betriebsstabilität. Jede Ebene baut auf der vorherigen auf und trägt zum Gesamterfolg bei. Die folgenden vier Dimensionen bilden das Fundament einer leistungsfähigen Cloud-Plattform, die mit Ihrem Unternehmen wachsen kann.

Eine der ersten Fragen beim Aufbau einer Cloud-Architektur lautet: Setzen wir auf einen einzigen Cloud-Anbieter oder verteilen wir unsere Workloads auf mehrere? Beide Ansätze haben eigene Vor- und Nachteile.
Die richtige Wahl hängt von Ihren Anforderungen ab: Unternehmen mit hohen Compliance-Anforderungen oder dem Wunsch nach Souveränität tendieren zu Multi-Cloud-Ansätzen. Wer Effizienz und schnelle Markteinführung priorisiert, fährt mit einem Single-Cloud-Ansatz oft besser. Wichtig ist: Die Entscheidung sollte strategisch getroffen werden, nicht zufällig oder nach dem Bauchgefühl.
Moderne Cloud-Architekturen setzen auf Modularität statt auf monolithische Anwendungen. Das Microservices-Prinzip zerlegt komplexe Anwendungen in kleinere, eigenständige Services, die unabhängig voneinander entwickelt, deployed und skaliert werden können.
Die Vorteile liegen auf der Hand: Teams können parallel arbeiten, einzelne Komponenten lassen sich gezielt skalieren und Technologiewechsel betreffen nur Teilbereiche statt des gesamten Systems. Wenn beispielsweise der Payment-Service mehr Last erfährt als der Rest der Anwendung, skaliert nur dieser und nicht die gesamte Infrastruktur.
Allerdings bringt diese Flexibilität auch Herausforderungen mit sich. Microservices erfordern kleinteilige Orchestrierung, durchdachtes API-Design und robustes Monitoring. Microservices erfordern eine sichere und kostenbewusste Konfiguration aller Services und ihrer Interaktionen. Container-Technologien wie Kubernetes oder Cloud Foundry helfen dabei, diese Komplexität zu meistern. Für Cloud Platform Engineering sind Microservices ideal, weil sie genau die Selbstverwaltung und Autonomie ermöglichen, die Teams brauchen.
Infrastructure as Code (IaC) ist das Fundament jeder modernen Cloud-Architektur. Statt Server und Netzwerke manuell zu konfigurieren, wird die gesamte Infrastruktur in Code beschrieben. Dadurch wird sie versioniert, testbar und reproduzierbar. Darüber hinaus ermöglicht IaC alle Vorteile etablierter Softwareentwicklungs-Workflows. Änderungen können vor dem Merge geprüft, dokumentiert und freigegeben werden, Konfigurationen automatisiert getestet werden, und fehlerhafte oder unsichere Setups lassen sich erkennen, bevor sie in produktive Umgebungen ausgerollt werden.
Tools wie Terraform, Pulumi, Azure Bicep oder AWS CloudFormation ermöglichen es, Infrastruktur wie Software zu behandeln. Die Vorteile dahinter sind groß:
In Kombination mit GitOps entsteht ein besonders leistungsfähiger Ansatz: Infrastruktur-Änderungen werden ausschließlich über Git-Workflows gesteuert und von CI/CD-Pipelines automatisiert ausgerollt. Das beschleunigt Prozesse und erhöht die Sicherheit, da manuelle Eingriffe auf ein Minimum reduziert werden.
Ein zukunftssicherer Aufbau einer Cloud-Architektur muss zwei zentrale Anforderungen erfüllen: Er muss mit wachsenden Anforderungen skalieren und gleichzeitig hochverfügbar bleiben.
Wichtig ist aber: Hochverfügbarkeit hat ihren Preis. Unternehmen müssen abwägen, welche Systeme kritisch sind und welches Ausfallrisiko akzeptabel ist. Nicht jede Anwendung braucht eine >99,99%-Verfügbarkeit.
Erst das Zusammenspiel aller Elemente stellt den erfolgreichen Aufbau einer Cloud-Architektur dar. Eine durchdachte Cloud-Architektur kombiniert die richtige Cloud-Strategie mit modularem Design, automatisierter Infrastruktur und eingebauter Resilienz. Unterstützen können dabei spezielle Frameworks wie das AWS, Google oder Azure Well-Architected Framework sowie Cloud Adoption Frameworks. Diese definieren Best Practices für Sicherheit, Kostenoptimierung, Betrieb und Performance. Durch den Security by Design Ansatz sorgen sie zudem dafür, dass Sicherheit von Beginn an berücksichtigt und integriert wird.
Weiterhin wichtig ist FinOps für eine kontinuierliche Kostenoptimierung. Cloud-Ressourcen sind zwar flexibel, können aber ohne Kontrolle schnell zu Kostenexplosionen führen. Monitoring, Tagging und regelmäßige Reviews sind dazu da, ein gutes Verhältnis zwischen Performance und Wirtschaftlichkeit zu schaffen.
Im Cloud Platform Engineering geht es vor allem darum, die Cloud-Infrastruktur als Produkt zu verstehen. Sie ist eine Plattform, die kontinuierlich an die Bedürfnisse der Nutzer angepasst wird. Die optimale Cloud-Architektur gibt es deshalb nicht als Standardlösung. Jedes Unternehmen muss basierend auf seinen Anforderungen, Ressourcen und Zielen die individuell richtigen Entscheidungen treffen. Ob Single- oder Multi-Cloud, Microservices oder modulare Monolithen, umfassende Redundanz oder akzeptables Risiko, die Architektur muss zur Organisation passen.
Wichtig ist, ein Verständnis für die grundlegenden Prinzipien zu schaffen. Infrastructure as Code ermöglicht Automatisierung, Flexibilität entsteht durch Modularität und durchdachte Skalierbarkeit und Ausfallsicherheit bringen Resilienz. Durch die Berücksichtigung dieser Elemente können Unternehmen eine zukunftssichere Cloud-Architektur schaffen, die mit dem Unternehmen wächst.

Die Digitalisierung des deutschen Gesundheitswesens hat 2025 einen Punkt erreicht, an dem Fortschritt und Ernüchterung gleichzeitig sichtbar werden. Mit der verpflichtenden Einführung zentraler Anwendungen wie E-Rezept und elektronischer Patientenakte, einer nahezu flächendeckenden Anbindung an die Telematikinfrastruktur sowie den gesetzlichen Rahmenbedingungen wie dem Digitalgesetz (DigiG), dem Gesundheitsdatennutzungsgesetz (GDNG) und dem Gesundheitsdigitalagenturgesetz (GDAG) sind die Voraussetzungen für digitale Versorgung so umfassend wie nie zuvor. Der E-Health Monitor 2025 zeigt jedoch, dass diese Infrastruktur im Versorgungsalltag bislang nur begrenzt Wirkung entfaltet.
Diese Diskrepanz ist kein kurzfristiges Umsetzungsproblem, sondern Ausdruck eines strukturellen Spannungsfeldes. Die TI wurde über Jahre primär als verpflichtende Infrastruktur etabliert, mit starkem Fokus auf Sicherheit, Regulierung und formaler Anbindung. Die Frage, wie digitale Anwendungen tatsächlich in bestehende Arbeitsabläufe integriert werden können, spielte in der frühen Phase eine untergeordnete Rolle. Entsprechend erleben viele Leistungserbringer die TI weniger als Entlastung, sondern als zusätzliche Ebene, die neben den bestehenden Prozessen betrieben werden muss.
Die Telematikinfrastruktur lässt sich als zentrales Rückgrat für digitale Kommunikation, Authentifizierung und den sicheren Austausch medizinischer Daten im Gesundheitswesen beschreiben. Technisch umfasst sie eine Vielzahl von Komponenten und Diensten von Identitätsmanagement über Kommunikationsdienste wie KIM bis hin zu Anwendungen wie ePA und E-Rezept. Die TI ist hochgradig sicherheitsorientiert und regulatorisch eng geführt. Gleichzeitig erhöht sie die technische und organisatorische Komplexität für die angeschlossenen Einrichtungen erheblich, insbesondere dort, wo neue Anwendungen tief in bestehende Systeme integriert werden müssen.
Ein zentrales Ergebnis aus den ersten Kapiteln des E-Health Monitors ist, dass die digitale Reife im Gesundheitswesen ziemlich unterschiedlich ausfällt. Der häufig pauschal beschriebene „Stand der Digitalisierung“ verdeckt erhebliche Unterschiede zwischen den Leistungserbringern. Während 64 Prozent der Praxen TI-Anwendungen zumindest regelmäßig bis intensiv nutzen, ist die Nutzungsintensität mit nur 13 Prozent der Krankenhäuser deutlich geringer. Zwar sind Krankenhäuser vollständig angebunden, doch der Anteil der Krankenhäuser, die die TI mittel bis intensiv im Alltag einsetzen, liegt deutlich unter dem ambulanten Niveau. Der TI-User-Index der gematik verdeutlicht diese Unterschiede zusätzlich: Während sich bei Arztpraxen 2025 ein deutlicher Anteil mittlerer und starker Nutzung der TI-Anwendungen zeigt, dominiert bei Krankenhäusern weiterhin der Bereich „keine Nutzung“. Selbst im Jahresvergleich 2024 zu 2025 bleibt der Anteil der TI aktiv nutzenden Kliniken gering, während Praxen ihre Nutzungsintensität sichtbar steigern konnten. Ein Befund, der vor allem die höhere strukturelle und organisatorische Komplexität des stationären Bereichs widerspiegelt.
Diese Unterschiede sind strukturell erklärbar. Ambulante Praxen arbeiten häufig mit vergleichsweise homogenen IT-Systemen und klar abgegrenzten Workflows, in die einzelne TI-Anwendungen punktuell integriert werden können. Krankenhäuser hingegen verfügen über hochkomplexe, historisch gewachsene IT-Landschaften mit zahlreichen Subsystemen, Schnittstellen und Abhängigkeiten. Neue digitale Anwendungen greifen hier in bestehende KIS-Strukturen ein, was Implementierungen zeitintensiv macht und stark von Herstellern abhängig ist. Digitale Prozesse lassen sich dadurch deutlich schwerer standardisieren und skalieren.
Hinzu kommt, dass technische Instabilitäten der TI keine Seltenheit sind. Der E-Health Monitor 2025 zeigt, dass technische Probleme bzw. die Fehleranfälligkeit für Kartenterminals und Konnektoren weiterhin ein relevanter Faktor sind.
Während Ausfälle oder Störungen im ambulanten Bereich häufig zu Mehrarbeit und Umgehungslösungen wie dem Faxgerät führen, können dieselben Probleme im stationären Umfeld ganze Prozessketten betreffen – von der Aufnahme über die Dokumentation bis hin zur Entlassung. Die Sensibilität gegenüber Systemstörungen ist entsprechend höher, was die Akzeptanz digitaler Anwendungen zusätzlich beeinflusst. Vor diesem Hintergrund ist die geringere Nutzungsintensität im stationären Bereich weniger als Defizit zu verstehen, sondern als Ausdruck der erheblich komplexeren Ausgangslage, unter der digitale Transformation im Krankenhaus stattfindet.
Diese Unterschiede spiegeln sich auch in dem TI-Atlas Dashboard der gematik wider. Zwar zeigt der „TI-Readiness-Index“, dass Apotheken, Arztpraxen und Krankenhäuser bis auf maximal 2 Prozent voll an die TI angeschlossen sind, doch der sogenannte TI-User-Index zeigt, dass aktive Nutzung und Integration stark variieren. Der TI-User-Index differenziert dabei zwischen starker, mittlerer, geringer und keiner Nutzung. Besonders auffällig ist, dass selbst bei nahezu vollständiger technischer Anbindung große Teile der Leistungserbringer TI-Anwendungen kaum oder gar nicht im Arbeitsalltag einsetzen.
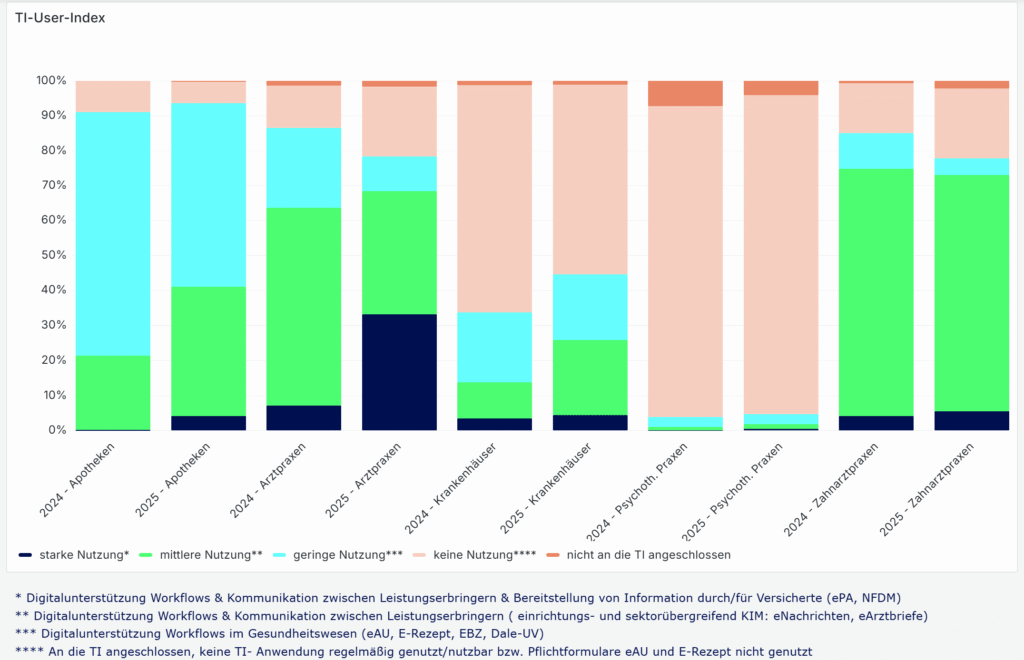
TI User Index der gematik (Screenshot vom 28.12.25, aufgerufen unter: TI Atlas Dashboard)
Auch in der Nutzung einzelner TI-Anwendungen zeigen sich deutliche Unterschiede. Während E-Rezept und der KIM-Dienst vergleichsweise stark genutzt werden, bleibt die Nutzung der elektronischen Patientenakte weiterhin deutlich hinter den Erwartungen zurück.
Der Stand der Telematikinfrastruktur im Jahr 2025 ist damit weniger eine Frage fehlender Technik als fehlender struktureller Passung. Die TI-Infrastruktur ist vorhanden, doch sie ist noch nicht konsequent auf die Realität unterschiedlicher Versorgungsbereiche ausgerichtet. Digitale Reife entsteht nicht nur durch Anschlussquoten oder gesetzliche Verpflichtungen, sondern durch technische Stabilität der TI, reduzierte Komplexität und eine Integration, die sich an realen Arbeitsabläufen orientiert.
Der E-Health Monitor 2025 macht deutlich, dass sich der Schwerpunkt der Digitalisierung auch noch in eine andere Richtung verschieben muss: weg von der Frage, ob digitale Infrastruktur existiert, hin zu der Frage, wie sie genutzt wird und von wem. Erst wenn digitale Anwendungen in ambulanten und stationären Settings gleichermaßen betriebsstabil und praxistauglich integrierbar sind, kann aus technischer Anbindung, digitale Reife und digitale Versorgung werden.
Der aktuelle „Stand der Digitalisierung“ ist damit weniger als Leistungsbewertung einzelner Akteure zu verstehen, sondern als Ausdruck der Komplexität der Aufgabe insgesamt. Die Unterschiede zwischen ambulantem und stationärem Bereich verdeutlichen, dass digitale Transformation im Gesundheitswesen nur dann gelingen kann, wenn Infrastruktur, Prozesse und organisatorische Realität konsequent zusammengedacht werden. Insbesondere dort, wo komplexe klinische Abläufe, hohe Integrationsanforderungen und kritische Versorgungsprozesse aufeinandertreffen

Die Cloud-Transformation verspricht Flexibilität, Skalierbarkeit und Kosteneffizienz. Bei der Migration ihrer IT-Infrastruktur in die Cloud zögern trotzdem nach wie vor viele Unternehmen. Sie haben Sicherheitsbedenken, befürchten Kontrollverluste und haben Angst vor unkalkulierbaren Kosten. Hier stellt sich allerdings die Frage: Sind diese Einwände noch berechtigt oder gibt es inzwischen für alle Cloud-Herausforderungen Lösungen? Wir thematisieren heute die häufigsten Bedenken rund um die Cloud und zeigen, wie vermeintliche Nachteile in der Cloud überwunden oder sogar in Vorteile umgewandelt werden können.
Ob in der Führungsebene oder in einzelnen Teams: Skepsis gegenüber der Cloud gibt es immer wieder. Die Einwände sind dabei in der Regel begründet und basieren auf realen Problemen und Herausforderungen. Besonders häufig nennen Unternehmen hier Sicherheitsrisiken, unübersichtliche Kosten, den Verlust direkter Kontrolle über die IT-Infrastruktur und die Abhängigkeit von einzelnen Anbietern. Wir erklären, was es mit diesen Nachteilen in der Cloud auf sich hat und wie Unternehmen sie adressieren können.

Die Sorge um Datensicherheit und Datenschutz steht oft an erster Stelle. Unternehmen haben Angst vor Cyberangriffen, Datenlecks oder unautorisiertem Zugriff auf sensible Daten. Professionelle Cloud-Anbieter investieren jedoch erheblich mehr in Sicherheitsmaßnahmen als es den meisten Unternehmen überhaupt intern möglich wäre. Moderne Cloud-Plattformen gehen Sicherheitsrisiken durch Verschlüsselung, Multi-Faktor-Authentifizierung, kontinuierliche Sicherheitsupdates und Compliance-Zertifizierungen nach internationalen Standards an.
Tipps für diese Herausforderung:
Die Kostenstruktur von Cloud-Infrastrukturen bereitet Unternehmen ebenfalls Sorgen. Traditionelle IT-Investitionen scheinen kalkulierbar und simpel, Cloud-Abrechnungen hingegen scheinen unübersichtlich und können durch nutzungsabhängige Abrechnungsmodelle zur Kostenfalle werden. Wichtig ist an dieser Stelle vor allem ein durchdachtes Finanzmanagement von Beginn an. Denn ohne Überwachung und Optimierung können Ausgaben tatsächlich schnell und unkontrolliert ansteigen.
Tipps für diese Herausforderung:
Beim Umstieg auf eine Cloud-Infrastruktur steht die IT-Infrastruktur nicht mehr im eigenen Rechenzentrum. Das sorgt für einen gefühlten Kontrollverlust und die Sorge, die Kontrolle über kritische Systeme abzugeben. Cloud-Plattformen stellen ihren Kunden jedoch umfassende Management-Tools, detaillierte Monitoring-Dashboards und APIs zur Automatisierung zur Verfügung, die schlussendlich sogar oft mehr Transparenz und Kontrolle schaffen als klassischen On-Premises-Lösungen.
Tipps für diese Herausforderung:
Die Sorge vor einem Vendor Lock-In ist durchaus begründet. Sind Unternehmen zu stark an einen einzelnen Cloud-Anbieter gebunden, erschwert das den potenziellen Wechsel zu anderen Anbietern und kann dadurch für hohe Kosten sorgen. Souveräne Cloud-Lösungen, die die Unabhängigkeit in verschiedenen Bereichen stärken, sind deshalb heute immer gefragter.
Tipps für diese Herausforderung:
Neben konkreten Einwänden stehen viele Unternehmen vor und während der Cloud-Transformation immer wieder vor Herausforderungen, sowohl technisch als auch organisatorisch. Strategische Planung und strukturiertes Vorgehen während der Transformation sind daher umso wichtiger, um die Vorteile der Cloud zu nutzen. Wir haben einige Tipps für Sie zusammengestellt.
Die technische Migration in die Cloud ist komplex und erfordert deshalb eine umfassende Planung. Legacy-Systeme müssen möglicherweise refaktoriert werden, Datenmigrationen erfordern sorgfältige Vorbereitung und bei der Integration mit bestehenden Systemen spielt die Kompatibilität eine wichtige Rolle. IT-Teams setzen sich mit Themen rund um Netzwerklatenz, Bandbreitenbeschränkungen und die Anpassung an cloud-native Architekturen auseinander und haben die Aufgabe, Sicherheits- und Compliance-Anforderungen in der neuen Umgebung zu gewährleisten. Benötigt wird dafür spezialisiertes Know-how, das viele Unternehmen in einem Cloud-Dienstleister suchen.
Tipps für technische Herausforderungen rund um die Cloud:
Dass die Cloud-Transformation nicht einfach ein einmaliges, technisches Projekt ist, ist längst kein Geheimnis mehr. Für eine erfolgreiche Cloud-Transformation benötigt es einen kulturellen Wandel, indem Mitarbeitende neue Arbeitsweisen erlernen und agiler sowie abteilungsübergreifender zusammenarbeiten. Um möglichen Widerständen frühzeitig zu begegnen, sind Change Management, klare Kommunikation und die Einbindung aller relevanten Mitarbeitenden entscheidend. Außerdem braucht es neue Verantwortlichkeiten für die Cloud-Umgebung und Transformation, sodass Prozesse und Best Practices entwickelt werden können.
Tipps für organisatorische Herausforderungen rund um die Cloud:
Bei den Nachteilen in der Cloud – ob Kontrollverlust, Vendor Lock-In, Sicherheit oder Kosten – handelt es sich letztendlich um Herausforderungen, denen Unternehmen sich während der Cloud-Transformation stellen müssen. Für die verschiedensten Einwände gibt es Lösungen in modernen Cloud-Ansätzen, die allerdings auch umgesetzt und gelebt werden müssen. Wichtig ist dabei vor allem eine durchdachte Planung, die sowohl technische als auch organisatorische Punkte berücksichtigt, ebenso wie eine klare Bewertung, in welchen Bereichen der Einsatz der Cloud sinnvoll ist und wo möglicherweise hybride Lösungen der richtige Weg sind, um sich nicht vollständig von gewohnten On-Premises-Umgebungen abzuwenden.
Rewion begleitet Ihr Unternehmen auf dem Weg in die Cloud. Mit umfassender Expertise in der Cloud-Transformation unterstützen wir Sie von der Strategieentwicklung über die Migration bis zum laufenden Betrieb und sorgen so dafür, dass Sie die Vorteile der Cloud optimal für sich nutzen können.

Viele Unternehmen nutzen heute Cloud-Dienste. Oft bedeutet das aber nur, Server bei Amazon, Microsoft oder Google zu mieten, statt im eigenen Rechenzentrum zu betreiben. Cloud Platform Engineering geht einen entscheidenden Schritt weiter: Es verwandelt diese gemieteten Ressourcen in eine maßgeschneiderte, selbstverwaltete Arbeitsumgebung für Teams. In diesem Artikel erklären wir, was genau dahintersteckt, wie Cloud Platform Engineering Teams aussehen und für welche Unternehmen sich dieser Ansatz lohnt.
Bei Cloud Platform Engineering geht es um den systematischen Aufbau und die Verwaltung von Cloud-Infrastrukturen als wiederverwendbare, selbstverwaltete Plattformen. Konkret bedeutet das: Viele Unternehmen setzen Cloud-Dienste einzeln und unabhängig voneinander ein, sodass jeder User sich mit allen Bestandteilen auseinandersetzen, sie verstehen und zusammenbauen muss. Cloud Platform Engineering funktioniert wie eine Art Bausatz-System und verwandelt die komplexen Einzelteile in standardisierte, einfach nutzbare Werkzeuge, die jeder im Team sofort verwenden kann. So wird die Cloud-Infrastruktur als Produkt behandelt, das kontinuierlich verbessert und an die Bedürfnisse der internen Nutzer angepasst wird.
Der Unterschied zur reinen Cloud-Administration ist dabei grundlegend. Cloud-Admins kümmern sich darum, dass Server laufen, Updates installiert werden und alles funktioniert. Cloud Platform Engineering hingegen gestaltet eine komplette Arbeitsumgebung, in der Teams selbstständig agieren können. Dabei verfolgt Platform Engineering drei zentrale Ziele:
Damit Cloud Platform Engineering funktioniert, braucht es klar definierte Aufgaben und Verantwortlichkeiten. Ein Platform Engineering Team besteht dabei aus verschiedenen Rollen:

Die Verantwortlichkeiten sind jedoch klar getrennt: Das Platform Team stellt die Infrastruktur bereit, DevOps optimiert Prozesse und Teams nutzen die Plattform für verschiedene Zwecke. Diese klare Aufgabenteilung schafft Effizienz und ermöglicht es jedem Team, sich auf seine Kernkompetenzen zu konzentrieren. Grundsätzlich geht es darum, eine funktionale Plattform für alle Nutzergruppen zu schaffen: Das kann beispielsweise ein lockeres Zusammenklicken von Services in einer Sandbox-Umgebung sein, aber auch das Enablement von Teams zum compliance-gerechten Deployment eines Workloads.
Cloud Platform Engineering ist kein Muss für jedes Unternehmen. Die Investition in eine umfassende Platform-Strategie lohnt sich vor allem unter bestimmten Kriterien:
Mehrere Nutzergruppen in einem Unternehmen
Unternehmen mit mehreren potenziellen Nutzergruppen profitieren am meisten. Wenn zehn oder mehr Mitarbeitende regelmäßig Cloud-Ressourcen nutzen, zahlt sich die Investition schnell aus. So bastelt nicht mehr jedes Team einzelne Lösungen, sondern alle nutzen dieselbe optimierte Plattform. Die Standardisierung reduziert Reibungsverluste und beschleunigt die Entwicklung über alle Teams hinweg.
Compliance im Mittelpunkt
Organisationen mit hohen Compliance-Anforderungen wie Banken, Versicherungen oder das Gesundheitswesen finden in Platform Engineering einen Verbündeten. Sie müssen nachweisen, dass ihre Systeme bestimmte Sicherheitsstandards erfüllen. Eine gut aufgebaute Plattform stellt automatisch sicher, dass jede Anwendung diese Anforderungen erfüllt, ohne dass Nutzer an unzählige Details denken müssen.
Wachstumsorientierung
Skalierungsorientierte Unternehmen, die schnelles Wachstum erwarten oder erleben, benötigen flexible Infrastrukturen. Wer in kurzer Zeit deutlich mehr Kunden erwartet, kann nicht auf manuelle Prozesse setzen. Cloud Platform Engineering ermöglicht es, neue Märkte schnell zu erschließen und Lastspitzen problemlos zu bewältigen.
Zu Beginn der Cloud-Migration
Unternehmen, die eine Cloud-Migration planen, sollten Platform Engineering von Beginn an berücksichtigen. Statt verschiedene Cloud-Services einzeln zu nutzen, schafft eine durchdachte Plattform-Strategie von Anfang an Struktur und vermeidet späteren Refactoring-Aufwand.
Weniger geeignet ist der Ansatz für sehr kleine Teams, Start-ups in frühen Phasen mit begrenzten Ressourcen oder Projekte mit einfachen Anforderungen, die sich kaum ändern. Hier ist der Aufwand oft größer als der Nutzen.
Cloud Platform Engineering geht weit über traditionelles Cloud Hosting hinaus und entwickelt sich zur wichtigen Grundlage für moderne Cloud-Infrastrukturen in Unternehmen. Statt einfach nur Server zu mieten, schaffen Unternehmen eine maßgeschneiderte Arbeitsumgebung, die Teams in der Anwendung das Leben erleichtert und gleichzeitig Sicherheit, Skalierbarkeit und Effizienz garantiert. Die verschiedenen Rollen arbeiten dabei Hand in Hand: Platform Engineers bauen die Grundlage, DevOps optimiert die Prozesse und Endnutzer können sich auf ihre jeweiligen Stärken konzentrieren. Für Unternehmen mit mehreren Nutzergruppen, hohen Sicherheitsanforderungen oder Wachstumsambitionen ist Cloud Platform Engineering eine strategische Investition, die sich langfristig auszahlt und den entscheidenden Wettbewerbsvorteil bringen kann.

Mobile Endgeräte wie Laptops, Smartphones und Tablets sind aus dem Unternehmensalltag längst nicht mehr wegzudenken. Sie ermöglichen flexibles Arbeiten, müssen aber auch durchdacht eingesetzt werden. Mobile Device Management macht die zentrale Verwaltung und Absicherung der Geräte möglich. Wie lässt sich eine solche MDM-Lösung aber einführen, ohne dabei den laufenden Alltag zu stören? Schließlich können die Geräte nicht einfach für mehrere Tage oder Wochen außer Betrieb genommen werden. Wir geben einen Überblick über mögliche Wege für die Mobile Device Management Integration in Unternehmen und geben Tipps für die Praxis.
Die Einführung eines Mobile Device Management Systems ist für viele Unternehmen ein Balanceakt: Einerseits müssen mobile Endgeräte zentral erfasst, verwaltet und abgesichert werden, andererseits darf der laufende Geschäftsbetrieb nicht beeinträchtigt werden. Es entstehen also verschiedene Herausforderungen:
Unternehmen haben also die Aufgabe, zuerst umfassend zu planen, schrittweise vorzugehen und vor allem transparent zu kommunizieren, um Mitarbeitende von den Veränderungen zu überzeugen.
Für eine erfolgreiche MDM-Integration sind drei große Schritte nötig: eine gründliche Vorbereitung, die schrittweise Implementierung und die dauerhafte Optimierung. Insbesondere die schrittweise Einführung sorgt dafür, dass die Implementierung nicht zu Schwierigkeiten im Arbeitsalltag führt.

Eine umfassende Vorbereitung ist die Grundlage für die erfolgreiche Einführung einer MDM-Lösung. In dieser Phase werden alle technischen, organisatorischen und kommunikativen Vorbereitungen getroffen, damit die spätere Implementierung reibungslos und nach klarem Plan ablaufen kann.
Für die tatsächliche Integration ist ein kontrolliertes und schrittweises Vorgehen der Weg der Wahl. Insbesondere, wenn es darum geht, den laufenden Betrieb nicht zu stören, sorgt ein durchdachter Prozess für Sicherheit und Akzeptanz.
Nach dem Rollout steht die wichtige Phase der Überwachung und Weiterentwicklung auf dem Plan. Kontinuierliche Evaluation und Anpassung sorgen dafür, dass das MDM-System langfristig funktioniert und akzeptiert wird.
Die Integration von Mobile Device Management im laufenden Betrieb ist zwar komplex, aber mit strukturiertem Vorgehen erfolgreich umsetzbar. Grundlage für eine erfolgreiche Einführung sind eine detaillierte Vorbereitung mit klarer Bestandsaufnahme, schrittweise Implementierung über Pilotphasen bis zum vollständigen Rollout und eine kontinuierliche Erfolgskontrolle und Optimierung. Auch transparente Kommunikation mit den Mitarbeitenden, Support und das Angebot von Schulungen spielen eine wichtige Rolle. Wichtig ist letztendlich, dass MDM im Detail geplant wird, bevor es in die Umsetzung geht. So entsteht am Ende ein stabiler Betrieb mit reduzierten Sicherheitsrisiken und hoher Produktivität, der flexible Arbeit sicher ermöglicht.

Die Europäische Union stellt die Cloud-Souveränität immer weiter in den Mittelpunkt: In aktuellen Ausschreibungen kommt erstmals ein umfassendes Cloud Sovereignty Framework zum Einsatz, das digitale Souveränität einerseits definiert und sie andererseits messbar macht. Unternehmen können dieses Framework damit als praktischen Leitfaden für ihre eigene Cloud-Strategie einsetzen. Denn die Frage nach Kontrolle, Unabhängigkeit und Rechtssicherheit in der Cloud betrifft längst nicht mehr nur öffentliche Organisationen, sondern alle Unternehmen, die kritische Daten und Workloads in die Cloud verlagern. Erfahren Sie in diesem Artikel, was das Cloud Sovereignty Framework beinhaltet und wie Sie es in der Praxis einsetzen können.
Das von der EU-Kommission entwickelte Cloud Sovereignty Framework basiert auf acht klar definierten Souveränitätszielen. Sie decken verschiedene Aspekte digitaler Unabhängigkeit ab und schaffen so einen ganzheitlichen Rahmen:
Einer der wichtigsten Faktoren des Cloud Sovereignty Frameworks ist die Möglichkeit zur praktischen Anwendung als Bewertungsinstrument in Unternehmen. Die EU nutzt ein zweistufiges Bewertungssystem, das Mindestanforderungen definiert und Differenzierung ermöglicht. Darauf können sich auch Unternehmen in ihrer eigenen Bewertung rund um die souveräne Cloud stützen.
Eine fünfstufige Skala (SEAL-Level: Sovereignty Effectiveness Assurance Levels) von SEAL-0 bis SEAL-4 definiert den Grad der Souveränität.

Ergänzend zum SEAL-Level berechnet die EU einen gewichteten Sovereignty Score. Die Gewichtung ist strategisch durchdacht: Operative Souveränität und Supply Chain Souveränität erhalten jeweils 20 %, da sie die praktische Unabhängigkeit und Resilienz am stärksten beeinflussen. Strategische und Technologie-Souveränität werden mit je 15 % gewichtet. Daten- und KI-, Rechts- und Sicherheitssouveränität erhalten je 10 %, da diese Bereiche bereits durch andere Regularien wie DSGVO, NIS2 oder DORA abgesichert sind. Nachhaltigkeit fließt mit 5 % ein.
Die anschließende Bewertung erfolgt durch offene und geschlossene Fragen an Cloud-Anbieter und wird ergänzt durch Nachweise und öffentliche Dokumentation. Gibt es Schwächen in einzelnen Bereichen, wird der Provider im Gesamtlevel heruntergestuft. Durch diesen Ansatz stellt die EU sicher, dass die Gesamtbewertung nicht durch gute Werte in einzelnen Bereichen beeinflusst werden kann.
Das Cloud Sovereignty Framework ist nicht nur für EU-Ausschreibungen relevant. Vielmehr können auch Unternehmen es als Grundlage für ihre eigene Cloud-Souveränitätsstrategie nutzen. Möglichkeiten zur Anpassung gibt es verschiedene:
Einerseits kann dieser Ansatz Unternehmen dabei helfen, die passenden Cloud Provider auszuwählen, andererseits kann auch die ganze Cloud-Strategie daran ausgerichtet werden. Das Cloud Sovereignty Framework schafft in jedem Fall einen sachlichen Rahmen, der Kriterien messbar und mit den individuellen Geschäftsanforderungen verknüpfbar macht.
Sowohl im öffentlichen Sektor als auch in der freien Wirtschaft hat das Cloud Sovereignty Framework die Chance, zum neutralen Standard für die Bewertung souveräner Cloud-Lösungen zu werden. Die Kombination aus acht klar definierten Dimensionen, einem abgestuften Bewertungssystem und einer transparenten Scoring-Methode schafft einen objektiven und vergleichbaren Rahmen für ein bisher oft individuell und subjektiv diskutiertes Thema. Unternehmen können das Framework als strategischen Leitfaden für ihre eigene Cloud-Strategie einsetzen und die einzelnen Kriterien an individuelle Bedürfnisse anpassen. Statt auf schwammige Souveränitätsversprechen zu vertrauen, können CIOs und IT-Verantwortliche jetzt konkrete Anforderungen definieren und ihren Fortschritt nachvollziehbar bewerten.







